Having created a simple application and installed our first NPM package, now things start to get serious. We want to start building out our real application, there will be more than one page, we’ll need client side JavaScript and CSS files. Organising all of this is important, you will have hundreds of files before you know it. This is where Express comes in.
If we install the basic Express npm package then we can get one of the biggest advantages for us, that is routing. I can define URLs and URL patterns that make up my application and then map functionality onto each one as I see fit. As you get more advanced you can start defining middleware steps that test security before allowing the user to get to a page. It makes your application configuration orders of magnitude simpler to look after. From my point of view at the moment, if you wanted to create a node.js web application that didn’t use Express then I’d want a very good reason why.
The basic installation is very simple, simply edit your package.json file and add express as a dependency:
Then, from the terminal, run “npm install”. You’ll see a bunch of new files installed under node_modules and can now start modifying the server.js file:
The key section is the line that starts app.get. This tells the application that it wants to listen for GET requests at the URL “/hello.txt” and what to do when someone requests that page, in this case just return some Hello World text. If the user requests a different URL then they’ll get an error. And of course you can also configure your routes to listen for PUT, POST and DELETE requests. And hopefully at this point you’ll see what’s happening, you now have the simple ability to support CRUD in your application, whether that be from web browsers or creating a REST API.
In the real world you’ll want to move your application logic off to other files before the server.js file becomes too large and unwieldy, so you can equally have lines like this:
In this example I’ve moved the business logic into a file called hello.js that lives in a subfolder from the root of my application: app/controllers/hello.js. You can put all of your hello world application functions into that file to keep things nicely organised.
In fact I actually move the routes themselves off to a separate file, so that the server.js really is just the instantiation of objects rather than any real business logic.
But this is not the extent of what Express can offer you. If you’re starting from scratch you’ll probably want to server up static content like CSS, images, client side JavaScript etc. Express can manage all of that for you as well, but it’s easier to create a new application:
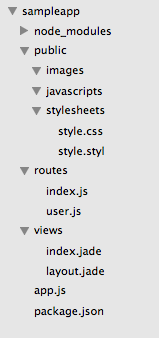
Structure of new demo app
The first line generates a new application with placeholder content including CSS and Jade files and a place to insert your own client side JavaScript. This is more complex than it sounds because, of course, all of the routes to the static files have to be configured. Once the app has been generated you can move to its directory, and then run an npm install to get all of the required modules as defined in the auto generated package.json file. Finally we can run the application with npm start. This kicks off the application listening on port 3000 and we can load it in the browser.
The point of a framework is to make life easier, there is no reason you couldn’t set all of this up manually yourself, but there really is no reason to. The rest of the world seems to use Express as a standard and it does everything you could possibly want, well at least I’ve not come across anything that I couldn’t do yet.